开运官网app AI 家具司理手记: badcase如何回流(下)

模子评测后的badcase处理是一门考究活,不是扫数问题都该丢给模子考研。本文将拆解badcase五大分类规范,揭告学问库轻视、行径模式、作风偏好等不同问题的处理政策,并共享如何构建金标集终了可纪念的模子迭代闭环。从业务视角启航,带你看懂如何让模子信得过越变越好。

评测产出的badcase如何信得过喂回模子?哪些该训、哪些不该训、训了反而更糟的有哪些。
上一篇写了我如何重作念单轮和多轮的评测框架——L1致命轻视一票否决、L2/L3分层扣分、多轮M1~M5五个专属维度。
但评测自己不创造价值,评测的产出必须能纠正模子。不然即是每周开会打一遍分,模子迭代了一版又一版,业务侧仍是以为不行——大众都很忙,但家具莫得变好。
这一篇讲的即是后半段:标完一堆badcase之后,如何把它信得过造成下一版模子的跳动。这部分是我跟大数据团队磨合最久的——不是因为他们不相助,是因为一运行大众对“什么badcase该训模子”的认知就不一样。
一、闭环长什么样

这张图的中枢信息唯有一条:badcase不是一个桶,是五个桶,每个桶的处理形状完全不同。
二、不是扫数badcase都该训模子
2.1学问库问题——皆备弗成训进模子
包括:事实轻视、集合不可用、信息过期
我专门拿了10条标了”事实轻视”的case复盘,发现7条是RAG调回错了对应文档,2条是学问库里那条数据自己就过期了,唯有1条算是模子”目田阐述”。
如若把这些case奏凯SFT进模子,等于让模子学会了一份自信但轻视的学问。后果有两个
学问库后续就算改对了,模子仍是会按训进去的错版块回答
模子对我方学过的内容置信度更高,反而更不肯意触发RAG调回
正确作念法:
调回错→优化embedding/加省份过滤/改chunk切分
学问库错→走数据处置经过,业务侧说明后修正源数据
模子目田阐述→少量,但确乎不错SFT,让它学“不细目就承认不知说念”
2.2行径模式问题——该SFT训
包括:暴力拒答、任务未闭环、无效反问、风马牛不联系
这些是模子”行径风俗”层面的问题——它知说念学问,但不知说念该如何用。这是SFT的经典题材。举个最典型的例子:
原恢复(被打0分):
“我是XX的销售助手,很对不起暂时未能找到与您的需求联系的信息。”
改写后野心恢复:
“您说的这个咱们莫得奏凯对应的家具,不外肖似需求不错望望XX/也不错转东说念主工盘考,您要不要试试?”
集会50~100对这样的(原恢复/改写后恢复),作念一轮针对性SFT,成果会有走漏改善。关节点:改写不是模子团队拍脑袋写,是业务侧来写。唯有业务侧知说念”在咱们的业务体系里,这个场景的最优恢复长什么样”。
2.3作风偏好问题——该DPO训,不该SFT
包括:冗余啰嗦、话术僵硬、排版繁芜
直观是”啰嗦了那就给它一个松弛版块去学”,但现实上SFT一个”松弛版”平素会带来模子举座抒发智力的退化——它会矫枉过正地造成”精雕细刻”,丢失本来好的雷同性抒发。
正确的作念法是DPO(奏凯偏好优化):给模子同期看(啰嗦版/简洁版),让它学的是两个版块之间的偏好关系,而不是只学其中一个。这样模子保留了抒发万般性,仅仅在”啰嗦vs简洁”这个维度上向你期许的主义歪斜。
咱们刻下积聚了大致200对作风偏好对,开运(中国)官方app分三类:
长度偏好(啰嗦版/简洁版)
口吻偏好(公式化版/当然版)
结构偏好(活水账版/结构化版)
2.4一张总结表
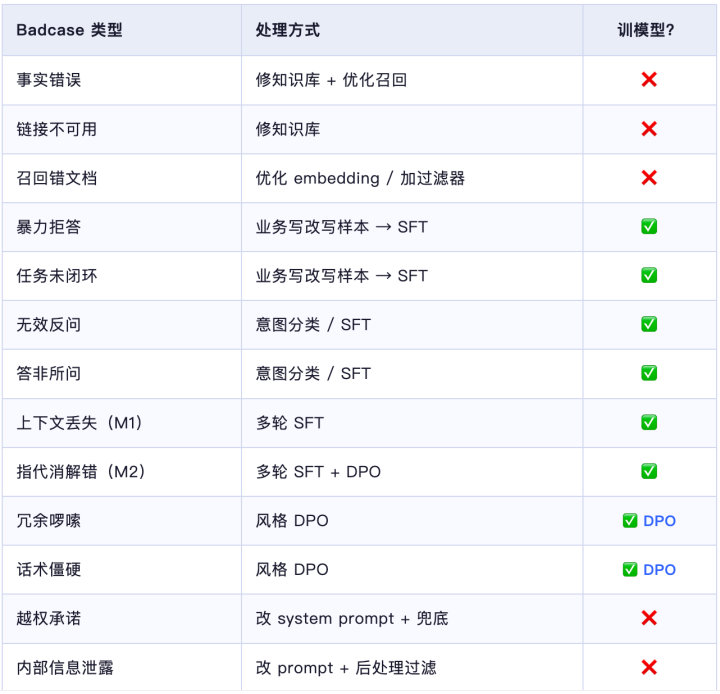
先对着这张表分类,然后才连络如何改。分类对了,处理形状当然就走漏了。
三、评测集必须固定一份”金标集”
每次新版模子出来,必须跑一遍200~500条的金标集,对比上一版各维度分数变化。
我的金标集是这样构造的:
30%高频通俗问(FAQ类,地板线)
40%中等业务场景(套餐/流量包/末端/升值业务,主战场)
20%多轮复杂场景(指代+意图切换搀和,天花板)
10%各样刁难(错别字、超长、夹杂方言、坏心绕过)
可提现游戏平台中国官网金标集要依期更新,但皆备弗成频繁更新。咱们的节拍是每季度补充10%新case、淘汰5%过期case。如若每个月都换一批,总结测试就失去比较基准了——你永恒不知说念是模子变好了,仍是题变通俗了。
四、总结测试要看分项变化,不单看总分
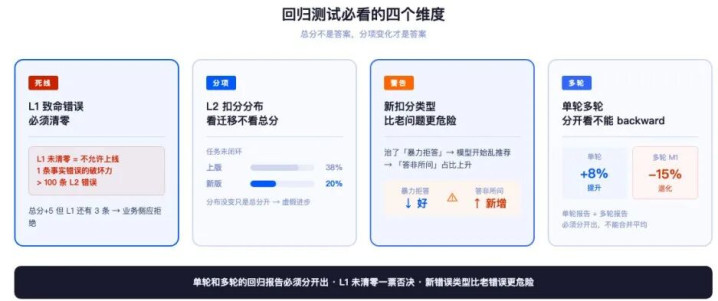
新版上线前,不要看”总分普及了3分”,要看:
4.1L1致命轻视是不是清零了
没清零不让上。这是死线。
一个版块如若总分普及了5分但L1轻视还有3条,业务侧应该拒却它。因为分娩环境下,1条L1轻视(比如说错价钱、伪造集合)的禁闭力弘远于100条L2轻视。
4.2L2严重项的扣诀别布有莫得变化
比如”任务未闭环”从38%降到20%——这是信得过特有趣的跳动。
如若散布险些没动,仅仅总分升高了,那很可能是金标集里通俗题答得更好了、艰难没动——这种“分数普及”是虚的。
4.3有莫得出现新的扣分类型
新轻视比老轻视更危急。
最常见的即是:为了治”暴力拒答”,模子学会了”什么都给你保举两款家具”,界限”风马牛不联系”的占比上来了。这种”按下葫芦浮起瓢”必须警悟。
4.4多轮M1~M5五个维度弗成backward
许多模子微调单轮变好了,多轮反而崩了——必须分开看。
我见过一次很惨烈的:模子团队为了治单轮的”风马牛不联系”,加强了模子的”主动话题雷同”智力,界限多轮的”高下文接管”分数掉了15个百分点。因为模子变得太”主动”了,不再老诚挚实地围绕用户的上一循环答。单轮和多轮的总结阐述必须分开出。
五、回流节拍:不要每周训,要按版块节拍走
频繁微调会让模子不领路——每周一个版块,业务侧压根来不足作念总结
小批量考研样本噪声大——30条样本里如若有5条标注有偏差,影响会被放大
没法定位是哪批数据起的作用
当今的节拍:

这个节拍走下来,每次新版块上线,业务侧能走漏地说出来”这版比较上版,在哪些维度普及了几许、有莫得新引入的问题”。而不是模子团队说”咱们又训了一版,你望望”,业务侧凭嗅觉点头或摇头。
六、回到阿谁原始问题
写这两篇著作之前,我问过我方一个问题:动作业务侧,我到底念念要什么?
谜底是:我念念要一套不错让模子迭代信得过变好的机制。不是评测漂亮的阐述开运官网app,不是95%的准确率,是一套能让”用户体验”这件事可被谋略、可被纠正、可被纪念的工程闭环。